
Shun Liu
Email: shunliu@buffalo.edu
I am in my final year at the Department of Computer Science, Shanghai University of Finance and Economics. During my undergraduate studies, I had the privilege to work at SUNY Buffalo, Dartmouth College, Zhejiang Lab, and Cardinal Operations. My research focuses on automating Large Language Models (LLMs) for feature discovery in tabular data, and vision foundation models with an emphasis on generalization and explainability.
Currently Working On:
- Biomedical Signals Analytics: Robotic Surgery (CVPR'25, under review), Endoscopy (ICLR'25, under review), Electronic Health Records (CIKM'24), Electrocardiogram (working paper)
- Human-Centered Vision: 2D Talking Head Synthesis, 3D Scene Reconstruction
I'm actively seeking CS/BME PhD intake starting Fall 2025!
News
- [11/2024] One paper (first-author) is submitted to CVPR'25 on biomedical text-vision learning!
- [09/2024] One paper is submitted to ICLR'25 on biomedical VQA!
- [07/2024] One paper is accepted by CIKM'24, thanks to all collaborators!
- [12/2023] Won Gold Medal (Top 1%) in CAFA5 Protein Function Prediction competition!
- [10/2023] Won Silver Medal (Top 2%) in LLM for Science Exam competition!
Research
Biomedical Signals Analytics
Leverage multimodel data complementaries for vision-language
task adaptation, e.g. VQA, Vision Grounding, etc.
- Robotic Surgery (CVPR'25, under review)
- Endoscopy (ICLR'25, under review)
- Electronic Health Records (CIKM'24)
- Electrocardiogram (working paper)
Human-Centered Vision
Exploring real-time representation & rendering algorithms for
high-fidelity generation of, e.g. face, head, etc.
- 2D Talking Head Synthesis
- 3D Scene Reconstruction
Publications
(* first author(s), ‡ corresponding author(s))
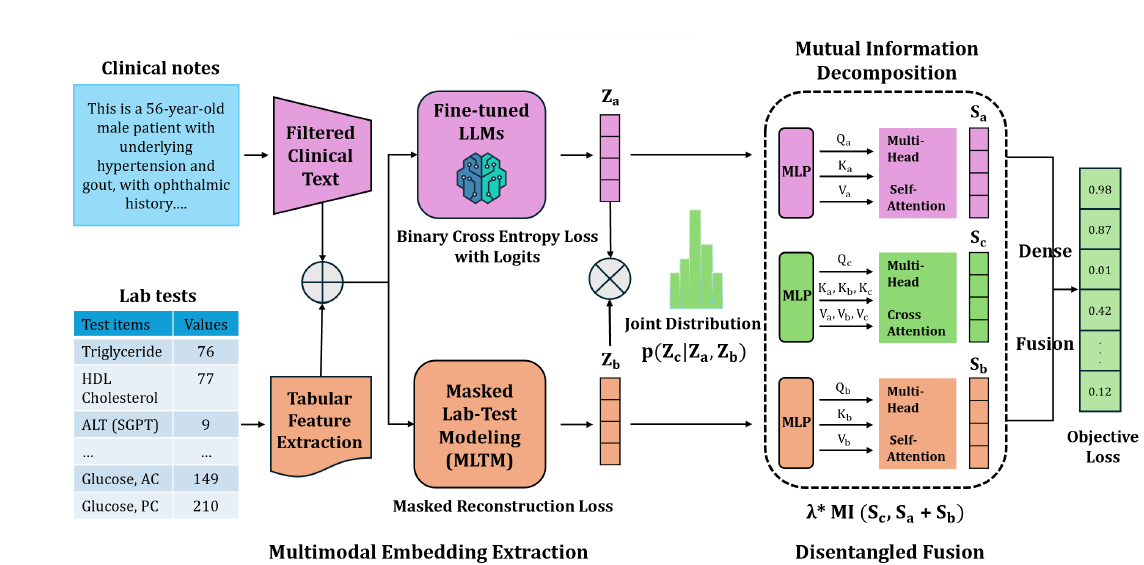
MEDFuse: Multimodal EHR Data Fusion with Masked Lab-Test Modeling and Large Language Models
Nguyen Minh Thao Phan*, Cong-Tinh Dao*, Chenwei Wu, Jian-Zhe Wang, Shun Liu, Jun-En Ding, David Restrepo, Feng Liu, Fang-Ming Huang, Wen-Chih Peng‡
Accepted, CIKM'24 (Short Research Paper Track)
We propose MEDFuse, a Multimodal EHR Data Fusion framework that incorporates masked lab-test modeling and large language models (LLMs) to effectively integrate structured and unstructured medical data. MEDFuse leverages multimodal embeddings extracted from two sources: LLMs fine-tuned on free clinical text and masked tabular transformers trained on structured lab test results.
[arxiv]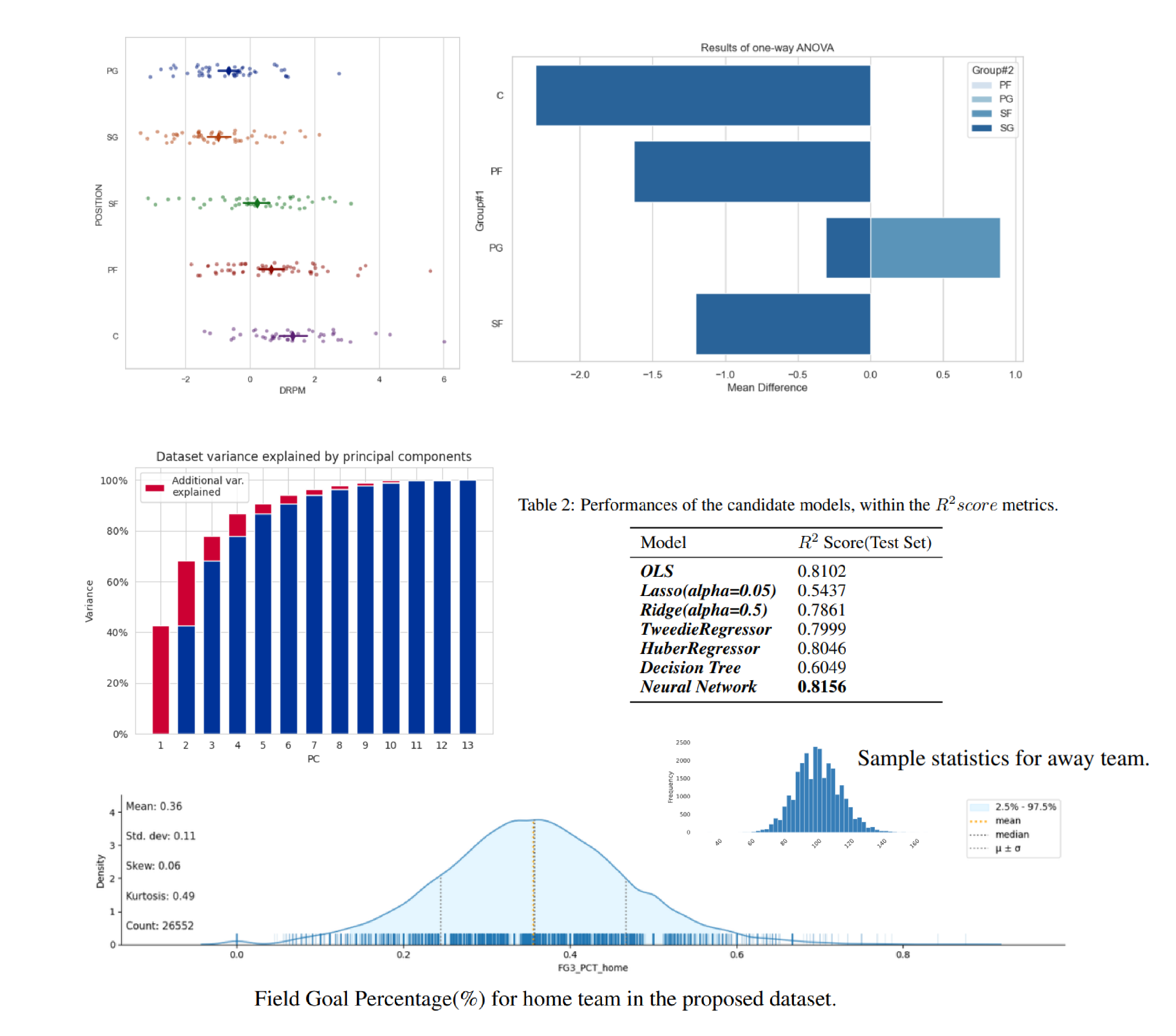
MAIF: Model-Agnostic Interpretation Framework in Machine Learning: A Comparative Study in NBA Sports
Shun Liu
arxiv, 2024
We proposed an innovative framework designed to reconcile the trade-off between model performance and interpretability. Our approach is centered around modular operations on high-dimensional statistics, which enable end-to-end processing while preserving interpretability. By fusing diverse interpretability techniques and modularized data processing, our framework sheds light on the decision-making processes of complex models without compromising their performance.
[arxiv]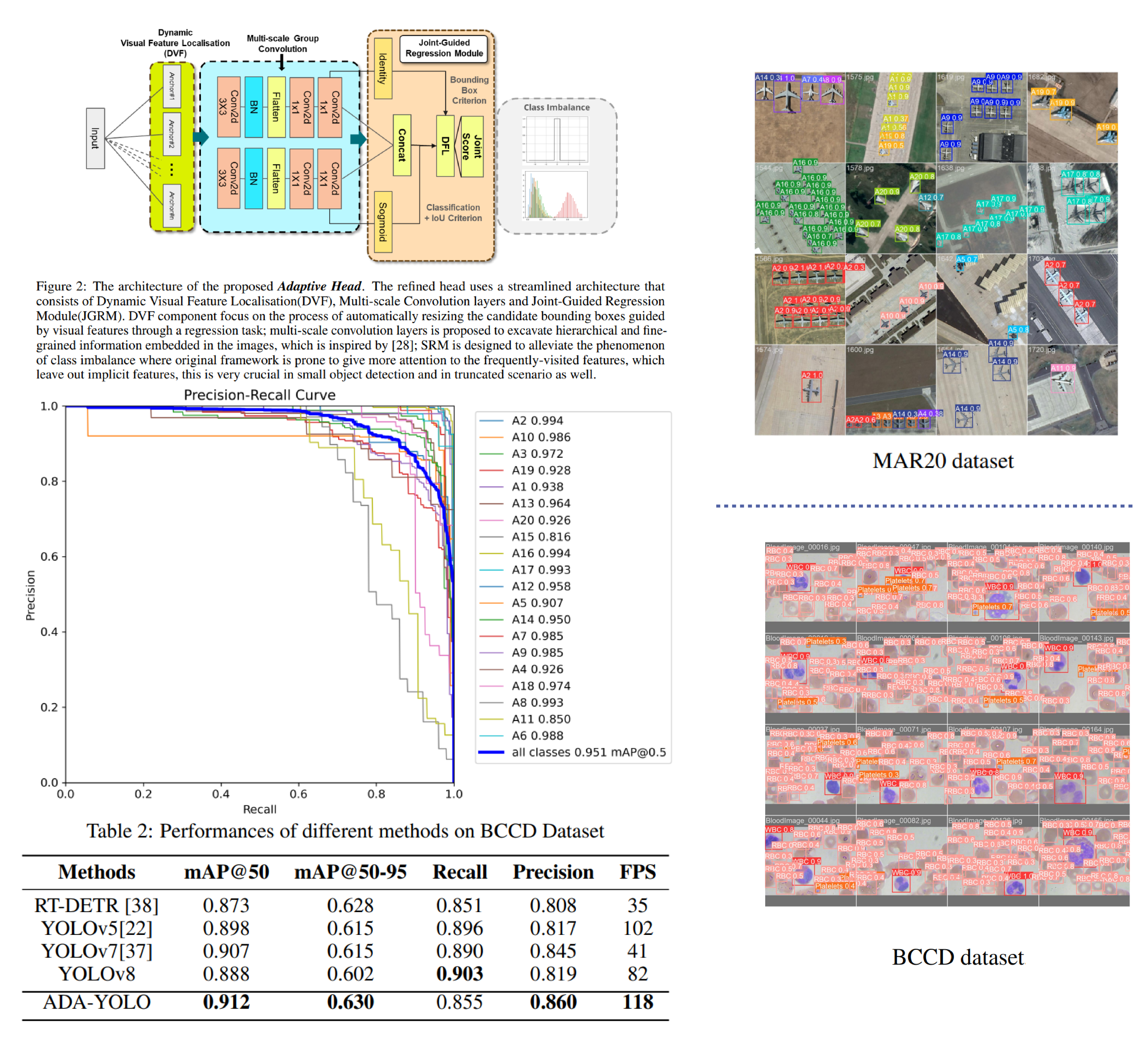
ADA-YOLO: Dynamic Fusion of YOLOv8 and Adaptive Heads for Precise Image Detection and Diagnosis
Shun Liu, Jianan Zhang, Ruocheng Song, Teik Toe Teoh‡
arxiv, 2024
We proposed a deep detector which leverages dynamic feature localization and parallel regression for computer vision tasks through an adaptive head module. Empirical experiments were conducted on the Blood Cell Count and Detection (BCCD) dataset to evaluate the effectiveness of ADA-YOLO. The results showed that ADA-YOLO outperforms the YOLOv8 model in mAP (mean average precision) on the BCCD dataset while using more than 3X less memory than YOLOv8.
[arxiv]Research Internships
- [12/2024-Present] Excit AI, 2D Talking Head Generation, 3D Scene Reconstruction
- [03/2024-12/2024] SUNY Buffalo, Biomedical Foundation Model, Multimodal Representation Learning
- [11/2023-02/2024] Dartmouth College, Trustworthy Large Language Models
- [08/2023-11/2024] Zhejiang Lab, Human Motion Generation
Contact Me!
Email: kevinliuleo@gmail.com
WeChat: 18017622619